Sqoop(SQL to Hadoop)看名字就能知道,它是传统数据库和Hadoop之间数据导入导出的一个桥梁。Sqoop是利用MapReduce进行数据传输的,速度还是很快的。lz的任务是将MySQL的一张表中的数据(18万+条)导入到HDFS中,所以就来尝试下Sqoop。
1.Sqoop服务搭建:
lz环境上Hadoop的版本是2.3.0,开始时使用的是Sqoop1.99.6,貌似是版本差异的原因,启动服务是报出异常java.sql.SQLNonTransientConnectionException:Connection closed by unknown interrupt,lz曾试图探究原因,但是失败了,^囧。所以lz遵从网友的建议,使用Sqoop1.99.4,这个问题便不再出现了。
其实Sqoop Server搭建很easy,有两个配置文件需要修改:
catalina.properties
将Hadoop、HBase以及Hive等所有需要的jar都添加到common.loader中,如下
|
1 |
common.loader=${catalina.base}/lib,${catalina.base}/lib/*.jar,${catalina.home}/lib,${catalina.home}/lib/*.jar,${catalina.home}/../lib/*.jar,/usr/lib/hadoop/*.jar,/usr/lib/hadoop/lib/*.jar,/usr/lib/hadoop-hdfs/*.jar,/usr/lib/hadoop-hdfs/lib/*.jar,/usr/lib/hadoop-mapreduce/*.jar,/usr/lib/hadoop-mapreduce/lib/*.jar,/usr/lib/hadoop-yarn/*.jar,/usr/lib/hadoop-yarn/lib/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/common/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/common/lib/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/hdfs/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/hdfs/lib/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/mapreduce/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/mapreduce/lib/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/yarn/*.jar,/app/cdh/hadoop-2.3.0-cdh5.0.0/share/hadoop/yarn/lib/*.jar |
sqoop.properties
三处log的输出地址需要修改:
|
1 2 3 |
org.apache.sqoop.log4j.appender.file.File=/log/sqoop/sqoop.log org.apache.sqoop.auditlogger.default.file=/log/sqoop/default.audit org.apache.sqoop.repository.sysprop.derby.stream.error.file=/log/sqoop/derbyrepo.log |
内置存储metastore的数据库目录:
|
1 |
org.apache.sqoop.repository.jdbc.url=jdbc:derby:/app/cdh/sqoop-1.99.4-bin-hadoop200/derby/repository/SQOOP;create=true |
Hadoop配置文件目录:
|
1 |
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/app/cdh/hadoop-2.3.0-cdh5.0.0/etc/hadoop/ |
配置好服务后,就可以启动了:
|
1 |
bin/sqoop2-server start |
2.MySQL导入HDFS:
找一台机器作为client连接server(随便找一台,只要网络通就可以)。Sqoop提供了很多方式连接server,这里lz使用CLI来操作:
|
1 |
bin/sqoop2-shell |
进入命令行,先设置server地址和端口(默认12000):
|
1 |
sqoop:000> set server --host pxene01 |
一切准备就绪,lz开始进行数据导入工作了。
(1)创建连接:
因为是从MySQL导入到HDFS中,所以分别要创建MySQL连接和HDFS连接,lz先看了下Sqoop默认提供的两种Connector:

通过name就能知道,id=1的是用于HDFS的,id=2的是用于传统数据库的。lz先创建HDFS的连接:

-cid 1中1指的是id=1的Connector,表明建立的是HDFS的连接,然后按提示输入名称及URI,最后用show命令看一下是否建立成功。
然后建立MySQL连接:
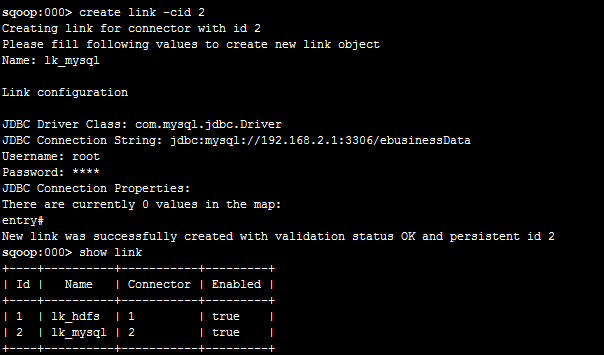
与第一个的步骤一样,就是需要填的内容多些。
(2)创建任务:

因为是从MySQL到HDFS,所以是-from 2 -to 1,这里2和1指的都是上面创建的link的id。然后就根据提示内容输入,不知道的直接回车,有选项的输入选项代号。
(3)执行任务:
|
1 |
sqoop:000> start job -jid 1 |
查看结果:
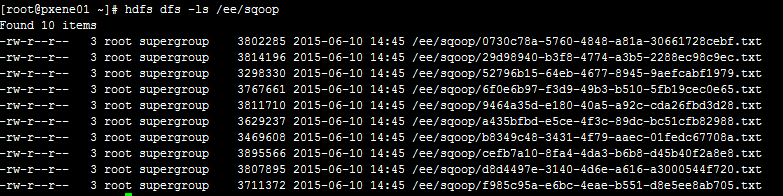
注:lz查询了很久,sqoop1.99.x这一系列的版本对于Hive和HBase的支持是很弱的。网上也有很多猿兄们询问此事,大多数还是在采用sqoop1.44来做Hive和HBase的导入导出。lz还是想等到sqoop2完善了对这俩的支持之后再做研究,所以这里就不介绍sqoop1.44了。
好文章!666,学习了