最近在使用Java8的新特性stream,因为LZ也在使用Spark,所以这种流式编程还是蛮顺手的,比以前的循环处理方便很多。stream基本用法网上有很多教程,这里就不在赘述了。这里LZ重点介绍stream的collect方法和其强大的工具类Collector。
先看下接口中声名的collect方法:
|
1 2 3 4 5 |
<R, A> R collect(Collector<? super T, A, R> collector); <R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner); |
第一个方法比较常用,比如将stream转化为集合:
|
1 2 3 |
Stream<String> stream = Stream.of("I", "love", "you", "too"); List<String> list = stream.collect(Collectors.toList()); |
其中Collectors类中提供了许多Collector接口的默认实现,这些实现能满足大部分的需求,否则要自己来实现Collector接口。Collector接口的3个泛型分别表示:
- T:输入元素类型(上例中的集合元素类型String)
- A:缩减操作的可变累积类型(上例中不存在)
- R:可变减少操作的结果类型(上例中的集合类型List)
这个方法是将N个输入元素T转化为1个输出元素R的过程,比如算平均数:
|
1 2 3 |
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); double d = stream.collect(Collectors.averagingInt(i -> i)); |
还有更复杂的groupby操作:
|
1 2 3 4 5 6 |
// Student {id, classId, score} List<Student> list = ...; Map<Integer, Double> map = list.stream().collect(Collectors.groupingBy(Student::getClassId, Collectors.averagingInt(Student::getScore))); |
第二个方法稍微复杂些,下面是该方法几个参数的接口:
|
1 2 3 4 5 |
@FunctionalInterface public interface Supplier<T> { T get(); } |
supplier用来创建最终的结果类型R(第一个例子中的List)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@FunctionalInterface public interface BiConsumer<T, U> { void accept(T t, U u); default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) { Objects.requireNonNull(after); return (l, r) -> { accept(l, r); after.accept(l, r); }; } } |
accumulator和combiner都实现了上面的接口,accumulator用来将输入元素转化为中间元素(第一个例子中将String插入List,T->A。这个例子中的中间元素和结果元素的类型相同)。combiner用来将中间元素转化为结果元素(第一个例子中将多个List合并为一个List,A->R),下图为整个合并的过程:
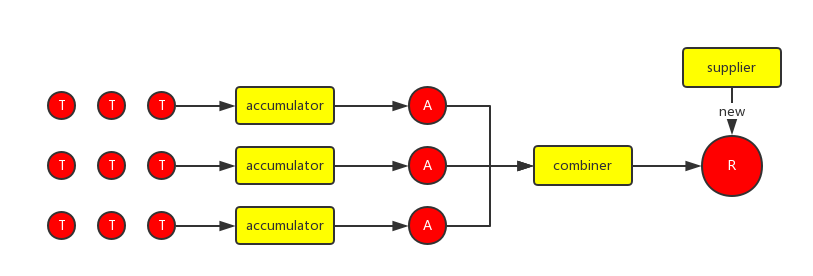
用这种方式改写下第一个例子:
|
1 2 3 4 5 6 7 8 9 |
Stream<String> stream = Stream.of("I", "love", "you", "too"); List<String> list = stream.collect(() -> { return new ArrayList<String>(); }, (List<String> list0, String str) -> { list0.add(str); }, (List<String> list1, List<String> list2) -> { list1.addAll(list2); }); |
1
好文章!666,学习了