为了简化命令行方式运行作业,Hadoop提供了一些辅助类,GenericOptionsParser便是其中的一个。一开始接触GenericOptionsParser还是在MapReduce的HelloWorld程序WordCount中,有这样一行代码:
... String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); ...
lz当时就有疑问,为什么要将args转为otherArgs呢。最近又接触到该类,便学习了下。
GenericOptionsParser能够识别参数中的标准命令行参数,并自动设置进Configuration中,这样避免了将配置写死在代码中,使MapReduce更加灵活。GenericOptionsParser支持一下命令行参数:
| 选项名称 | 描述 |
| -D property=value | 将指定值赋值给确定的Hadoop配置属性。覆盖配置文件里的默认属性或站点属性,或通过-conf选项设置的任何属性 |
| -conf filename… | 将指定文件添加到配置的资源列表中。这是设置站点属性或同时设置一组属性的简便方法 |
| -fs uri | 用指定的URI设置默认文件系统。这是-D fs.default.name=uri的快捷方式 |
| -jt host:port | 用指定主机和端口设置jobtracker。这是-D mapred.job.tracker= host:port的快捷方式 |
| -files file1,file2,… | 从本地文件系统(或任何指定模式的文件系统)中复制指定文件到jobtracker所用的共享文件系统(通常是HDFS),确保在任务工作目录的MapReduce程序可以访问这些文件(要想进一步了解如何复制文件到tasktracker机器的分布式缓存机制) |
| -archives archive1,archive2,… | 从本地文件系统(或任何指定模式的文件系统)复制指定存档到jobtracker所用的共享文件系统(通常是HDFS),打开存档文件,确保任务工作目录的MapReduce程序可以访问这些存档 |
| -libjars jar1,jar2,… | 从本地文件系统(或任何指定模式的文件系统)复制指定JAR文件到被jobtracker 使用的共享文件系统 (通常是HDFS),把它们加入MapReduce任务的类路径中。这个选项适用于传输作业需要的JAR文件 |
GenericOptionsParser的实现代码中有这样的逻辑:
...
if (line.hasOption("libjars")) {
conf.set("tmpjars",
validateFiles(line.getOptionValue("libjars"), conf),
"from -libjars command line option");
URL[] libjars = getLibJars(conf);
if (libjars!=null && libjars.length>0) {
conf.setClassLoader(new URLClassLoader(libjars, conf.getClassLoader()));
Thread.currentThread().setContextClassLoader(
new URLClassLoader(libjars,
Thread.currentThread().getContextClassLoader()));
}
}
...
代码里判断是否含有默认可识别的命令,如果有就将该配置加入到conf中。
当然,还有更加简便的方法(其实lz是很懒的,不想多写代码),就是通过ToolRunner来运行应用程序,ToolRunner内部调用GenericOptionsParser。通过ToolRunner来运行的程序必须实现Tool接口,再继承Configured实现默认的方法。
先上图:
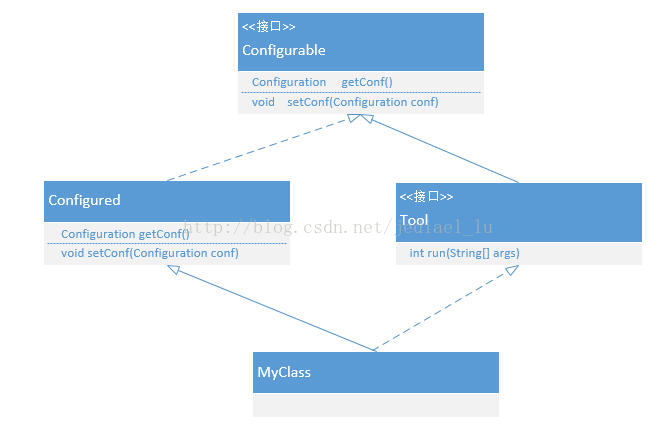
再贴源码:
Configurable接口:
public interface Configurable {
void setConf(Configuration conf);
Configuration getConf();
}
Tool接口:
public interface Tool extends Configurable {
int run(String [] args) throws Exception;
}
Configured类:
public class Configured implements Configurable {
private Configuration conf;
public Configured() {
this(null);
}
public Configured(Configuration conf) {
setConf(conf);
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return conf;
}
}
要使用ToolRunner.run()方法来调用Job类:
ToolRunner.run(new MyJob(), args); ToolRunner.run(conf, new MyJob(), args);
这里如果不传入conf,方法里会自动生成一个Configuration类的对象。
来看下run()的具体实现:
public static int run(Configuration conf, Tool tool, String[] args)
throws Exception{
if (conf == null) {
conf = new Configuration();
}
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
tool.setConf(conf);
String[] toolArgs = parser.getRemainingArgs();
return tool.run(toolArgs);
}
该方法调用了GenericOptionsParser,并将getRemainingArgs()后的代码传入了Job主类的run()方法中。
Job主类要继承Tool接口,实现Configured,Job的代码逻辑就写在唯一需要实现的run()方法里:
public class MyJob extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
...
Configuration conf = getConf();
...
return job.waitForCompletion(true) ? 0 : 1;
}
}
这里getConf()返回的conf就是在ToolRunner.run()中传入的conf。
好文章!666,学习了